What causes Overfitting in random forest?
Thereof, how do you stop Overfitting in random forest?
1 Answer
- n_estimators: @Falcon is wrong, in general the more trees the less likely the algorithm is to overfit. So try increasing this.
- max_features: try reducing this number (try 30-50% of the number of features).
- max_depth: Experiment with this.
- min_samples_leaf: Try setting this to values greater than one.
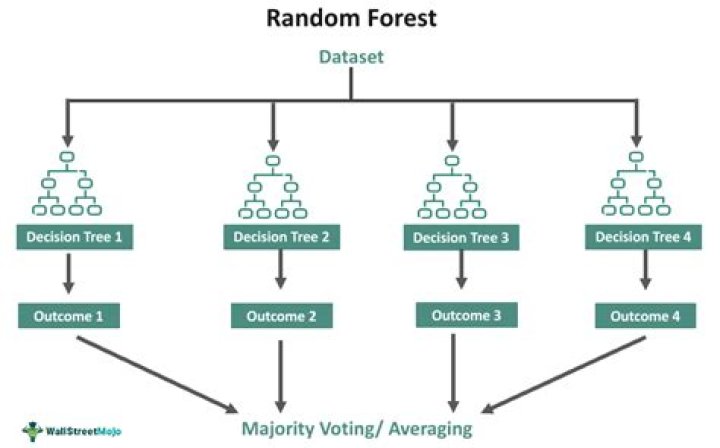
Furthermore, how does random forest predict? The random forest is a classification algorithm consisting of many decisions trees. It uses bagging and feature randomness when building each individual tree to try to create an uncorrelated forest of trees whose prediction by committee is more accurate than that of any individual tree.
Herein, what are the causes of Overfitting?
Overfitting happens when a model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data. This means that the noise or random fluctuations in the training data is picked up and learned as concepts by the model.
What causes overfitting in decision tree?
Decision trees are prone to overfitting, especially when a tree is particularly deep. This is due to the amount of specificity we look at leading to smaller sample of events that meet the previous assumptions. This small sample could lead to unsound conclusions.
Related Question Answers
Can random forest Underfit?
This is due to the fact that the minimum requirement of splitting a node is so high that there are no significant splits observed. As a result, the random forest starts to underfit. You can read more about the concept of overfitting and underfitting here: Overfitting in Machine Learning.How do you know if you are Overfitting?
Overfitting can be identified by checking validation metrics such as accuracy and loss. The validation metrics usually increase until a point where they stagnate or start declining when the model is affected by overfitting.Why is random forest better than decision tree?
Random forests consist of multiple single trees each based on a random sample of the training data. They are typically more accurate than single decision trees. The following figure shows the decision boundary becomes more accurate and stable as more trees are added.How do you counter Overfitting?
Handling overfitting- Reduce the network's capacity by removing layers or reducing the number of elements in the hidden layers.
- Apply regularization , which comes down to adding a cost to the loss function for large weights.
- Use Dropout layers, which will randomly remove certain features by setting them to zero.
Why Random Forest is the best?
Random forest is a flexible, easy to use machine learning algorithm that produces, even without hyper-parameter tuning, a great result most of the time. It is also one of the most used algorithms, because of its simplicity and diversity (it can be used for both classification and regression tasks).Why is random forest better than linear regression?
The averaging makes a Random Forest better than a single Decision Tree hence improves its accuracy and reduces overfitting. A prediction from the Random Forest Regressor is an average of the predictions produced by the trees in the forest.What is the difference between decision tree and random forest?
Each node in the decision tree works on a random subset of features to calculate the output. The random forest then combines the output of individual decision trees to generate the final output. The Random Forest Algorithm combines the output of multiple (randomly created) Decision Trees to generate the final output.What is Overfitting a model?
Overfitting is a modeling error that occurs when a function is too closely fit to a limited set of data points. Overfitting the model generally takes the form of making an overly complex model to explain idiosyncrasies in the data under study.How do I fix Overfitting and Underfitting?
Using a more complex model, for instance by switching from a linear to a non-linear model or by adding hidden layers to your neural network, will very often help solve underfitting. The algorithms you use include by default regularization parameters meant to prevent overfitting.How do I stop Overfitting and Overfitting?
How to Prevent Overfitting or Underfitting- Cross-validation:
- Train with more data.
- Data augmentation.
- Reduce Complexity or Data Simplification.
- Ensembling.
- Early Stopping.
- You need to add regularization in case of Linear and SVM models.
- In decision tree models you can reduce the maximum depth.
Is Overfitting always bad?
The answer is a resounding yes, every time. The reason being that overfitting is the name we use to refer to a situation where your model did very well on the training data but when you showed it the dataset that really matter(i.e the test data or put it into production), it performed very bad.How do you know if you are Overfitting or Underfitting?
We can determine whether a predictive model is underfitting or overfitting the training data by looking at the prediction error on the training data and the evaluation data. Your model is underfitting the training data when the model performs poorly on the training data.How do you check Overfitting in random forest?
There are some parameters of random forest that can be tuned for the model's better performance. n_estimators: The more trees, the less likely the algorithm is to overfit. So try increasing this parameter. The lower this number, the closer the model is to a decision tree, with a restricted feature set.How do I know if my model is Overfitting or Underfitting?
- Overfitting is when the model's error on the training set (i.e. during training) is very low but then, the model's error on the test set (i.e. unseen samples) is large!
- Underfitting is when the model's error on both the training and test sets (i.e. during training and testing) is very high.
How does Regularisation prevent Overfitting?
That's the set of parameters. In short, Regularization in machine learning is the process of regularizing the parameters that constrain, regularizes, or shrinks the coefficient estimates towards zero. In other words, this technique discourages learning a more complex or flexible model, avoiding the risk of Overfitting.How can we prevent Underfitting?
Techniques to reduce underfitting :- Increase model complexity.
- Increase number of features, performing feature engineering.
- Remove noise from the data.
- Increase the number of epochs or increase the duration of training to get better results.
Is random forest deep learning?
What's the Main Difference Between Random Forest and Neural Networks? Both the Random Forest and Neural Networks are different techniques that learn differently but can be used in similar domains. Random Forest is a technique of Machine Learning while Neural Networks are exclusive to Deep Learning.Why do we use random forest?
In random forest we use multiple random decision trees for a better accuracy. Random Forest is a ensemble bagging algorithm to achieve low prediction error. It reduces the variance of the individual decision trees by randomly selecting trees and then either average them or picking the class that gets the most vote.Is random forest regression or classification?
Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean/average prediction (regression) of theIs Random Forest bagging or boosting?
tl;dr: Bagging and random forests are “bagging” algorithms that aim to reduce the complexity of models that overfit the training data. In contrast, boosting is an approach to increase the complexity of models that suffer from high bias, that is, models that underfit the training data.Is Random Forest good for regression?
In addition to classification, Random Forests can also be used for regression tasks. A Random Forest's nonlinear nature can give it a leg up over linear algorithms, making it a great option. However, it is important to know your data and keep in mind that a Random Forest can't extrapolate.How many decision trees are there in a random forest?
Accordingly to this article in the link attached, they suggest that a random forest should have a number of trees between 64 - 128 trees. With that, you should have a good balance between ROC AUC and processing time.How do you improve random forest accuracy?
8 Methods to Boost the Accuracy of a Model- Add more data. Having more data is always a good idea.
- Treat missing and Outlier values.
- Feature Engineering.
- Feature Selection.
- Multiple algorithms.
- Algorithm Tuning.
- Ensemble methods.